| 本帖最后由 rogerskys 于 2022-2-14 19:54 编辑
原文:https://i4t.com/5260.html
效果图
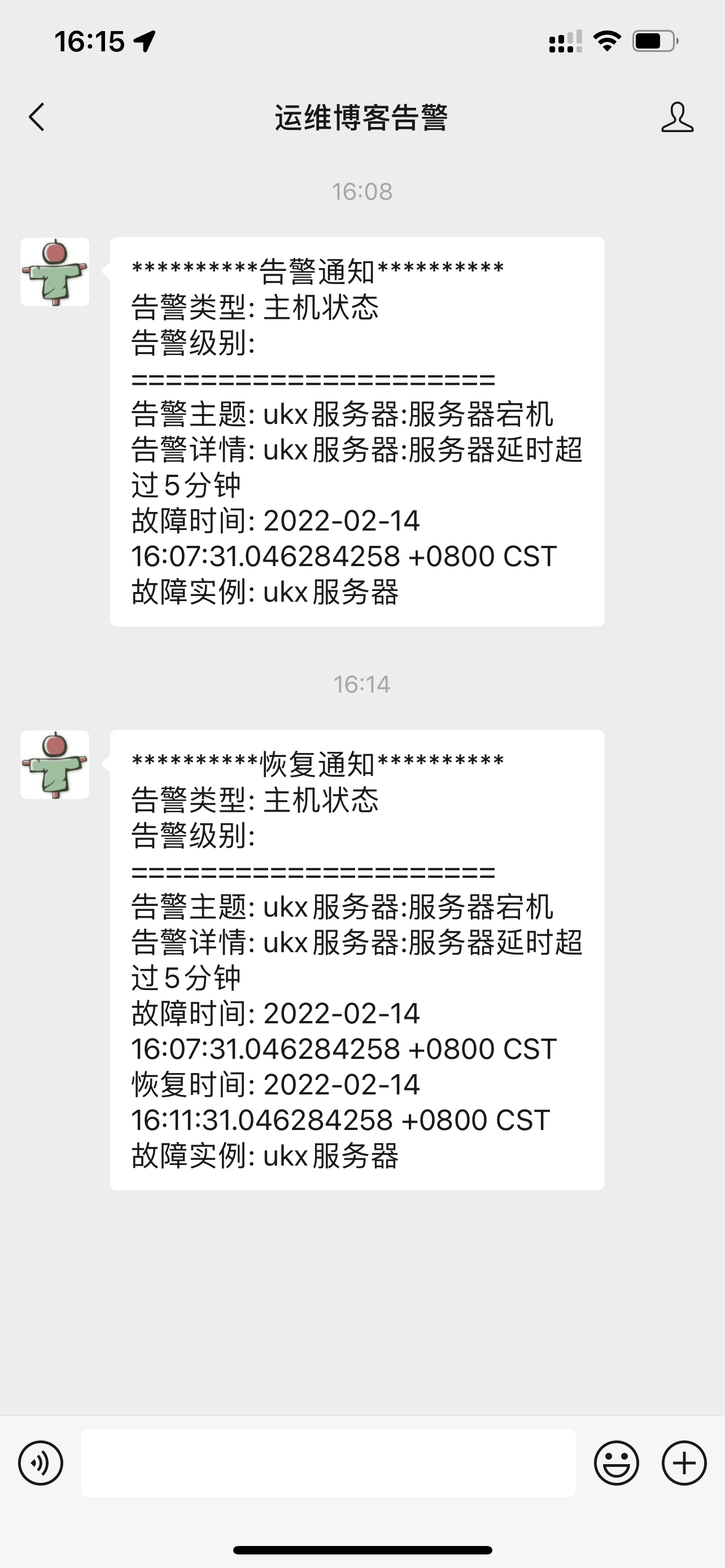
使用方法
AlertManager 安装
部署Alertmanager目前包含二进制包、容器以及源码方式安装,官方推荐使用docker容器运行,这里默认我就安装docker容器运行
AlertManager配置文件编写
mkdir /etc/prometheus/alertmanager
vim /etc/prometheus/alertmanager/config.yml
global:
resolve_timeout: 5m
http_config:
follow_redirects: true
smtp_hello: localhost
smtp_require_tls: true
pagerduty_url: ‘https://events.pagerduty.com/v2/enqueue’
opsgenie_api_url: ‘https://api.opsgenie.com/’
wechat_api_url: ‘https://qyapi.weixin.qq.com/cgi-bin/ ‘
wechat_api_corp_id: wwcxxxxxxxx #企业id
victorops_api_url: ‘https://alert.victorops.com/integrations/generic/20131114/alert/’
route:
receiver: abcdocker #对应下面receivers中的name
continue: false
group_wait: 30s
group_interval: 3m
repeat_interval: 3m
receivers:
– name: abcdocker
wechat_configs:
– send_resolved: true
http_config:
follow_redirects: true
api_secret: f2xxxxx # 申请企业微信应用后生成的密码
corp_id: wwc1xxx
message: ‘{{ template "wechat.default.message" . }}’
api_url: https://qyapi.weixin.qq.com/cgi-bin/
to_user: CongYuHong #发送到某一用户也可以 @all 就是群组全员发送
to_party: ‘{{ template "wechat.default.to_party" . }}’
to_tag: ‘{{ template "wechat.default.to_tag" . }}’
agent_id: "1000004" #申请企业微信应用id
message_type: text
templates:
– /etc/alertmanager/template/*.tmpl #告警模板路径
编写发送企业微信告警模板
mkdir /etc/prometheus/alertmanager/template -p
vim /etc/prometheus/alertmanager/template/WeChat.tmpl
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
**********告警通知**********
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
{{- end }}
=====================
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.description }}
故障时间: {{ $alert.StartsAt.Local }}
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例: {{ $alert.Labels.instance }}{{- end -}}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
**********恢复通知**********
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
{{- end }}
=====================
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.description }}
故障时间: {{ $alert.StartsAt.Local }}
恢复时间: {{ $alert.EndsAt.Local }}
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例: {{ $alert.Labels.instance }}{{- end -}}
{{- end }}
{{- end }}
{{- end }}
docker运行alertmanager,这里我挂载写的是目录,因为告警格式也需要挂载下
docker run -d -p 9103:9093 –name alertmanager
-v /etc/prometheus/alertmanager:/etc/alertmanager
-v /usr/share/zoneinfo/Asia/Shanghai:/etc/localtime
docker.io/prom/alertmanager:latest
–config.file=/etc/alertmanager/config.yml
#由于时区问题,我们将alertmanager时区挂载为上海
安装完alertmanager可以直接访问 IP:9013
四 、告警规则设置
创建我们创建目录 (最好和prometheus配置文件在一个目录)
mkdir /etc/prometheus/rules #创建高级规则目录
接下来我们添加Node exporter告警规则
[root@prometheus rules]# vim /etc/prometheus/rules/node_exporter.yaml
groups:
– name: 主机状态-监控告警
rules:
– alert: 主机状态
expr: up == 0
for: 1m
labels:
status: 很是严重
annotations:
summary: "{{$labels.instance}}:服务器宕机"
description: "{{$labels.instance}}:服务器延时超过5分钟"
– alert: CPU使用状况
expr: 100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 60
for: 1m
labels:
status: 通常告警
annotations:
summary: "{{$labels.mountpoint}} CPU使用率太高!"
description: "{{$labels.mountpoint }} CPU使用大于60%(目前使用:{{$value}}%)"
– alert: 内存使用
expr: 100 -(node_memory_MemTotal_bytes -node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes ) / node_memory_MemTotal_bytes * 100> 80
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 内存使用率太高!"
description: "{{$labels.mountpoint }} 内存使用大于80%(目前使用:{{$value}}%)"
– alert: IO性能
expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 流入磁盘IO使用率太高!"
description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"
– alert: 网络
expr: ((sum(rate (node_network_receive_bytes_total{device!~’tap.*|veth.*|br.*|docker.*|virbr*|lo*’}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 流入网络带宽太高!"
description: "{{$labels.mountpoint }}流入网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}"
– alert: 网络
expr: ((sum(rate (node_network_transmit_bytes_total{device!~’tap.*|veth.*|br.*|docker.*|virbr*|lo*’}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 流出网络带宽太高!"
description: "{{$labels.mountpoint }}流出网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}"
– alert: TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} TCP_ESTABLISHED太高!"
description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"
– alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80
for: 1m
labels:
status: 严重告警
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率太高!"
description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
后续如果我们还需要添加别的告警,我们可以直接在/etc/prometheus/rules目录下单独创建一个yaml设置告警即可
五、Prometheus 集成 AlertManager
我们需要重新修改Prometheus容器,将/etc/prometheus整个挂载到prometheus容器上去
docker run -d -p 9090:9090
–restart=always
–name prometheus
-v /data/prometheus:/data/prometheus
-v /etc/prometheus:/etc/prometheus/
registry.cn-beijing.aliyuncs.com/abcdocker/prometheus:v2.18.1
–config.file=/etc/prometheus/prometheus.yml
–storage.tsdb.path=/data/prometheus
–web.enable-admin-api
–web.enable-lifecycle
–storage.tsdb.retention.time=30d
接下来是prometheus配置文件的修改
vim /etc/prometheus/prometheus.yml
rule_files:
– ‘rules/*.yaml’
#添加告警规则路径,我这里使用了docker 挂载并且prometheus.yaml和rules是同一个目录,所以直接写相对路由,也可以写成绝对路径
Prometheus 配置文件添加alertmanager地址
alerting:
alertmanagers:
– static_configs:
– targets: [‘10.0.24.13:9103’] #alertmanager地址+端口号
完整配置文件如下
global:
scrape_interval: 60s
evaluation_interval: 20s
scrape_timeout: 15s
rule_files:
– ‘rules/*.yaml’
scrape_configs:
– job_name: abcdocker_node
scrape_interval: 3s
static_configs:
– targets: [‘11111:9090’]
labels:
instance: prometheus-server
– targets: [‘11111.frps.cn’]
labels:
instance: 博客服务器
– targets: [‘1.1.1.61:9100’]
labels:
instance: ukx服务器
– targets: [‘1.1.1.1:9100’]
labels:
instance: 海外下载站
– targets: [‘82.1xxxxx:9100’]
labels:
instance: frp服务器
alerting:
alertmanagers:
– static_configs:
– targets: [‘10.0.24.13:9103’]
修改完配置文件,重启prometheus,我们就可以在Alert中看到监控项了
https://i4t.com/5260.html
原文看的更清楚
|
 嘟嘟社区
嘟嘟社区