| 读秀电子书库2.0-5.0全集及多个电子书库合计1440万册,四种方案本地存储使用自建私人图书馆
收纳1440万册电子书,自建本地私人电子书图书馆,四种方案简要介绍
基于百度网盘,快速搜索定位文件;
上手容易操作方便使用简单,自由增删编辑,不占本地空间,节约大量经济成本与时间成本。
一、方案一 标准秒传码模式
1、秒传码基础知识
一行一个文件,每行的数据按照以下方式排列:
<完整 MD5> # <片段 MD5> # <文件长度> # <文件名>
完整 MD5:文件整体的 MD5 数据,唯一;
片段 MD5:文件前 256KiB 的 MD5 数据,唯一;
文件长度:文件的字节长度,唯一;
文件名:文件的名称,可随意更改。
组合成如下格式(仅供测试用途):
2cc94452264ca5199f37eaae1049178e#2cc94452264ca5199f37eaae1049178e#8#1024.txt
2、必备脚本
秒传链接提取
https://greasyfork.org/zh-CN/scripts/424574
3、小结:
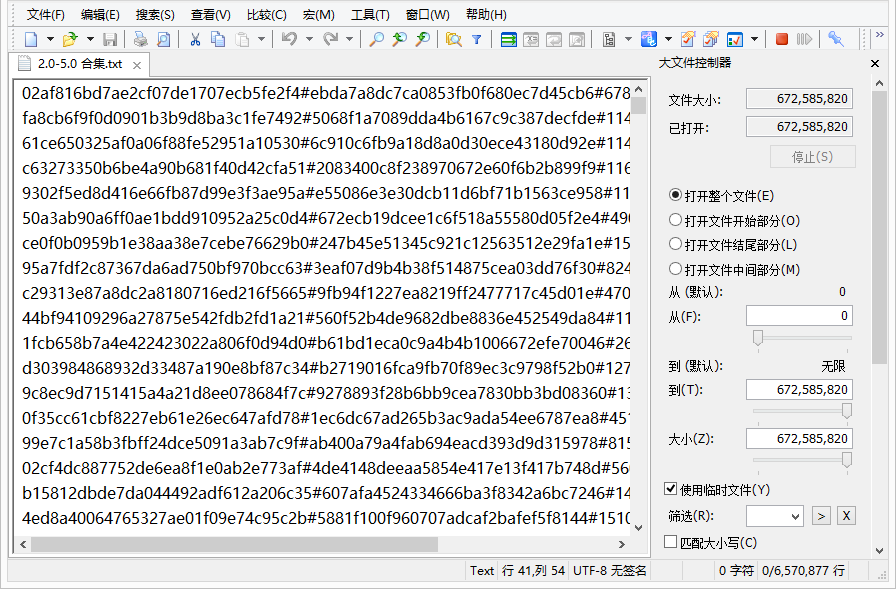
①.目前已通过该方式提取读秀书库2.0-5.0合计657万册电子书秒传链接,形成本地秒传书库;
②.结合本地搜索软件、电子书解密合成工具包、全国图书馆联盟等工具,实现私人图书馆完美运行;
③.详细使用教程见上一篇文章:https://hostloc.com/thread-1058456-1-1.html
④.秒传链接提取脚本已支持简版秒传码提取,即“极速生成”功能,生成、转存更方便,更节约时间。
二、方案二 文件目录模式
百度网盘并未提供文件目录功能,我们可通过python、缓存数据库文件相结合的方式导出。
1、python源代码
如下所示:
https://paste.ubuntu.com/p/5Wyt32nf5g/
保存为baidu.py文件,直接运行,出现如下界面:
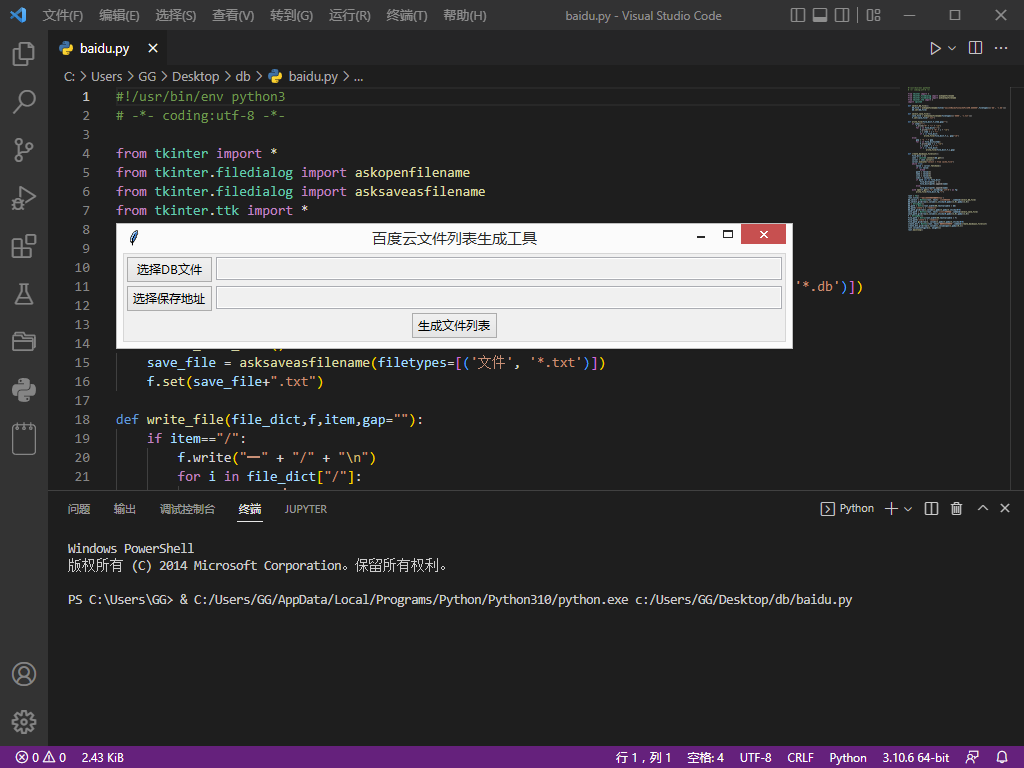
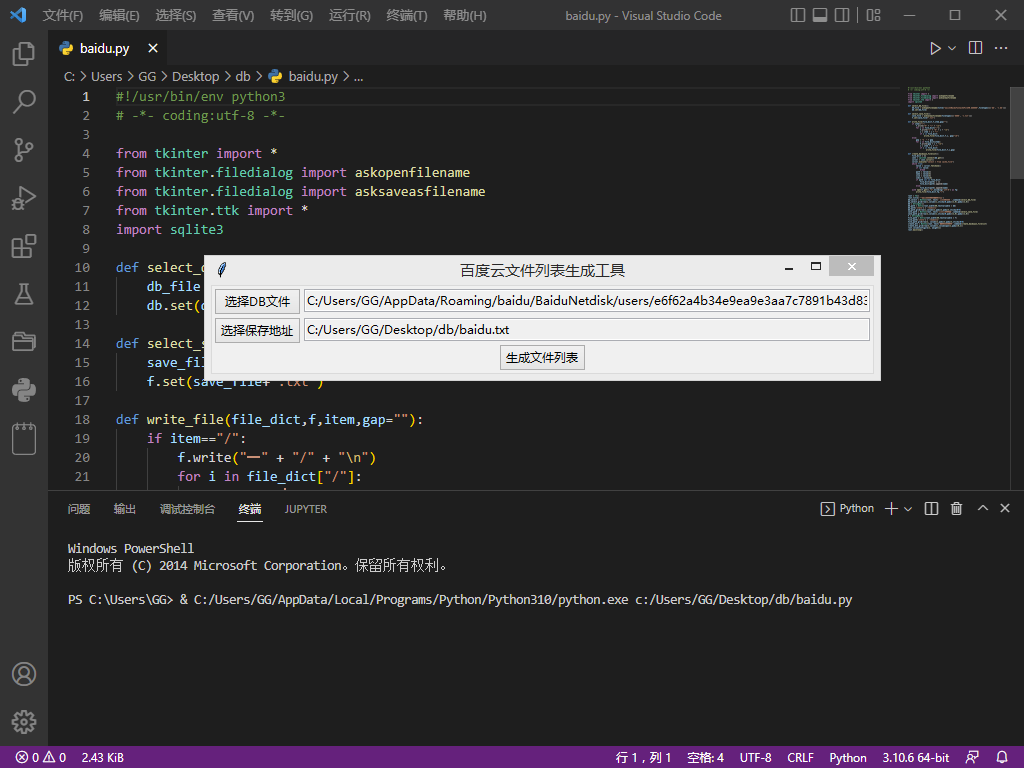
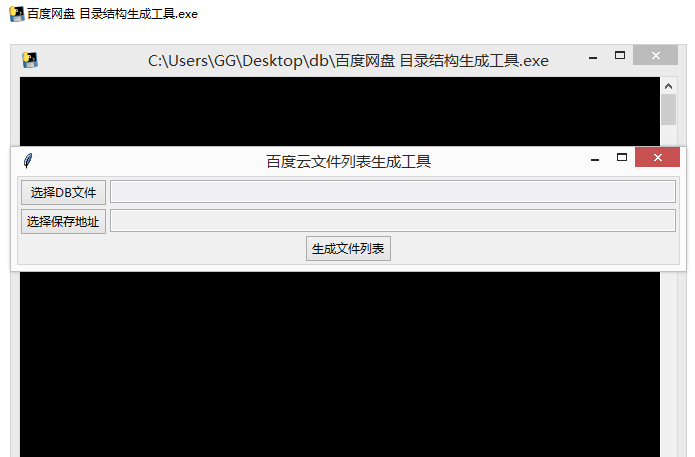
也可使用已打包好的程序,直接双击运行,如下所示:
2、百度网盘缓存数据库文件
位于网盘安装目录下users文件夹内,文件名为BaiduYunCacheFileV0.db,找到后在对话框里面选中该文件;
然后选择保存地址,最终生成文件列表,清晰展示所有文件分布情况,一目了然。

3、小结:
①.只需要python源代码(或打包好的程序)和本地缓存数据库;速度与数据库文件大小相关,文件越大速度越慢;
②.获取百度网盘文件目录,保存本地,在该目录中查找文件,手动定位网盘中的位置,下载保存。
三、方案三 开发者接口模式(由于字数限制,大量文字省略,隔壁平台有完整内容)
百度网盘开放了多功能接口,包括图片处理、音视频、上传下载文件、附件、nas、文件提取和设备管理等等;
我们主要是用到了上传文件、下载文件和文件提取的接口。
百度网盘开放平台需要申请
https://pan.baidu.com/union#/
https://pan.baidu.com/union/apply/
https://pan.baidu.com/open/platform
完整流程
a.获取access_token
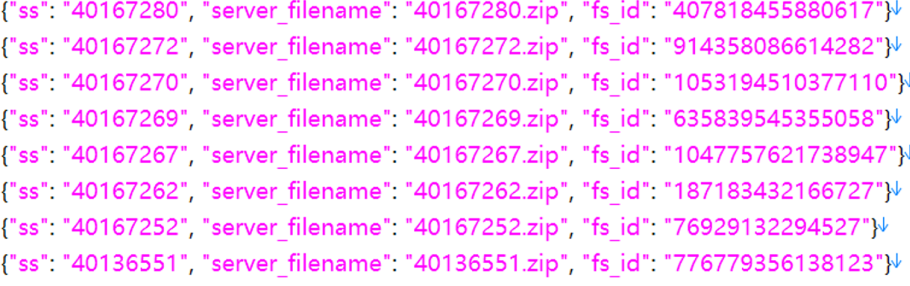
b.获取文件的fsid
c.查询文件信息
d.拿到dlink,配合curl即可下载
e.获取文件名称server_filename,配合fs_id,形成本地文档
百度网盘开放平台帮助文档
https://pan.baidu.com/union/document
https://pan.baidu.com/union/doc
小结:
①.目前暂未看到有完整封装程序,所以需具备一定开发能力,稍有门槛;
②.响应参数里面有丰富数据,如fs_id、server_filename、size和md5等等,这些数据是方案一秒传脚本的基础。
四、方案四 数据库简版秒传模式
简版秒传码与标准秒传码相比,只是没有包含片段MD5数据;
同样一行一个文件,每行的数据按照以下方式排列:
<完整 MD5> # <文件长度> # <文件名>
组合成如下格式(仅供测试用途):
2cc94452264ca5199f37eaae1049178e#8#1024.txt
1、完整缓存本地数据库
参考方案二,在百度网盘安装目录下users文件夹内,找到BaiduYunCacheFileV0.db;
多次刷新百度网盘客户端文件目录,观察数据库文件大小变化,确保已经缓存完整。
2、使用Navicat Premium导出数据库
①.将BaiduYunCacheFileV0.db直接拖进Navicat Premium左侧栏;
②.双击cache_file;
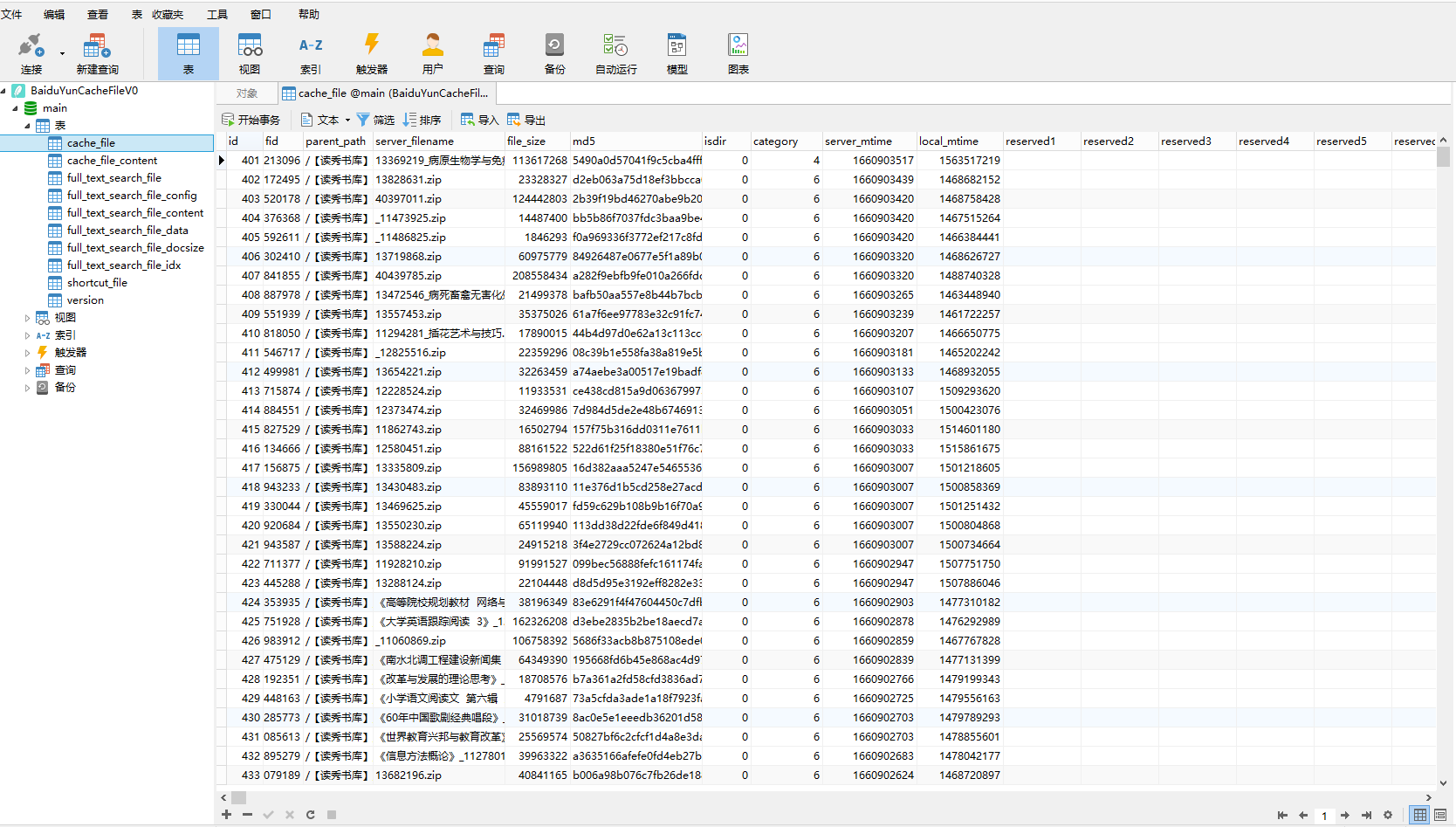
③.点击右下角齿轮,取消勾选限制记录,获取整个文件记录,进度时间视数据库大小而定;
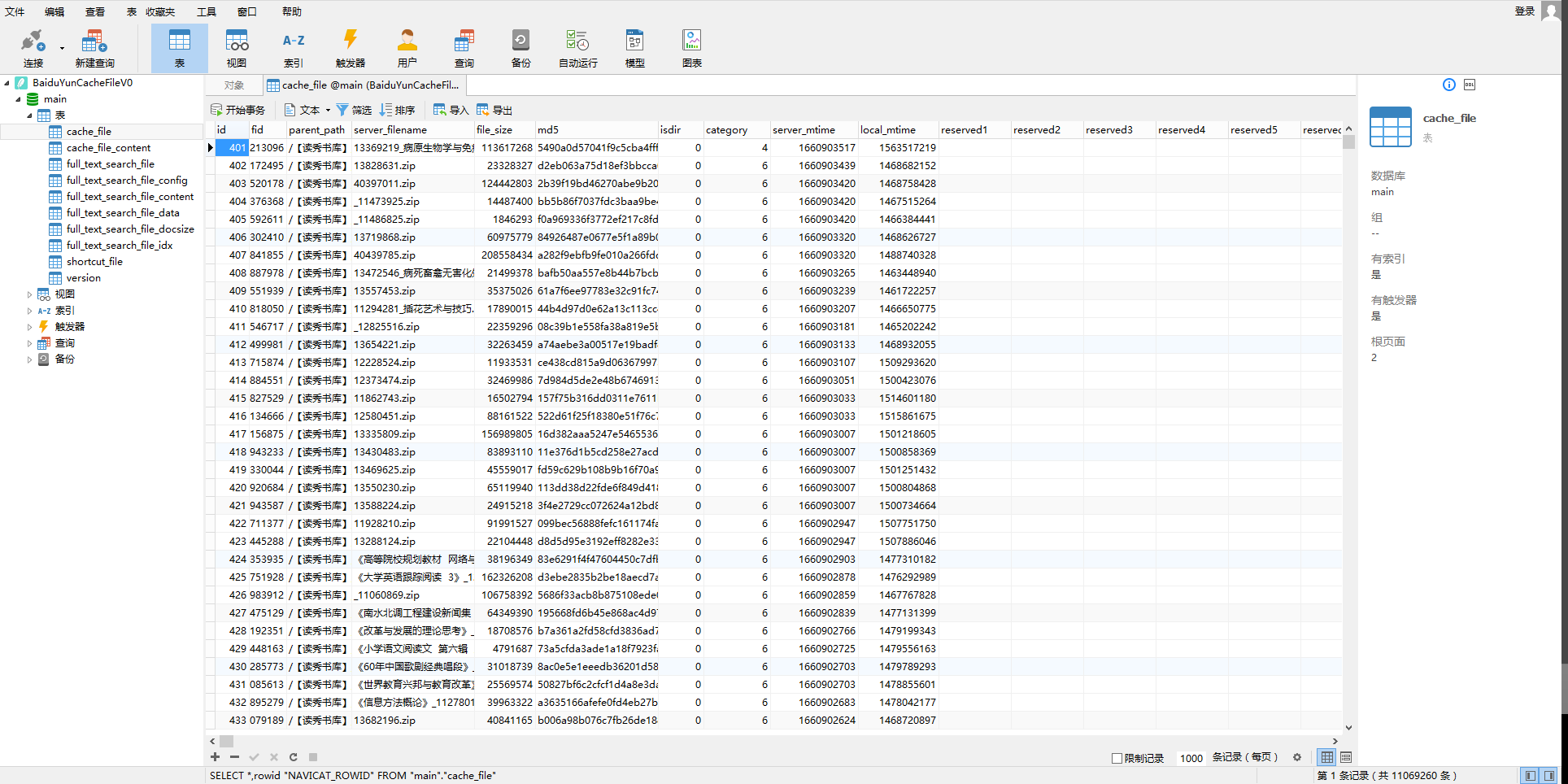
④.依次点击顶部的 查询,新建查询,查询创建工具;
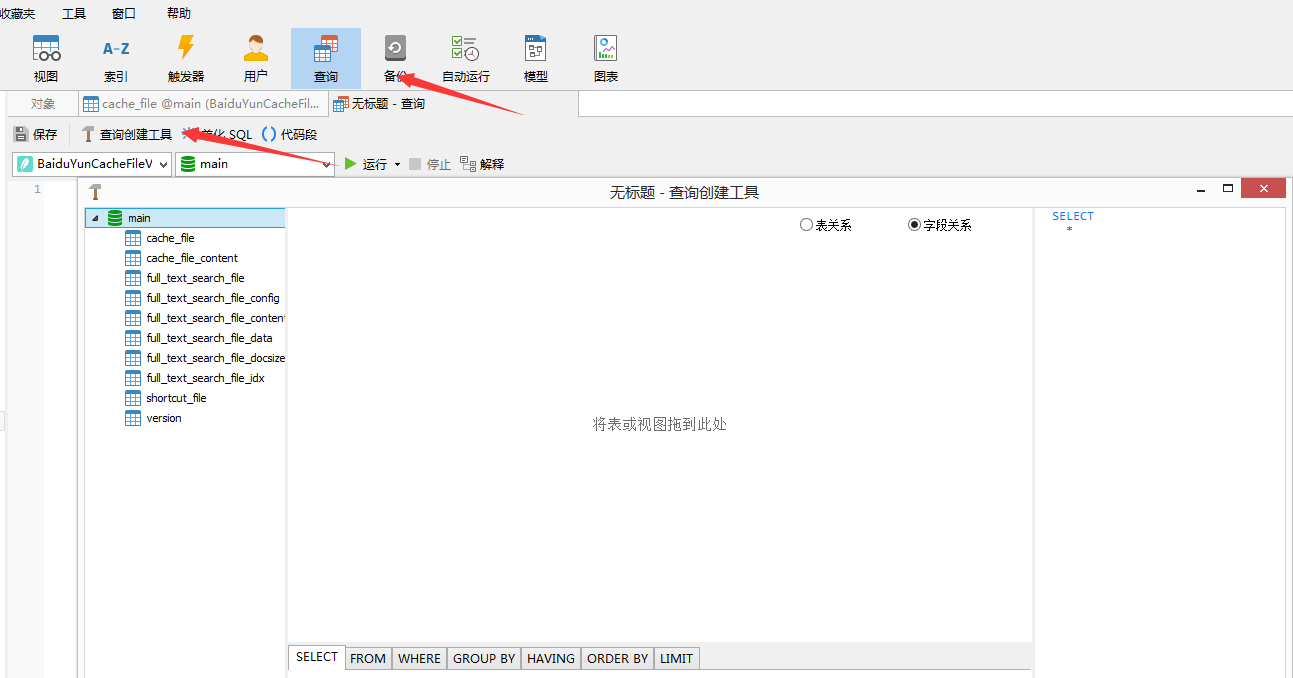
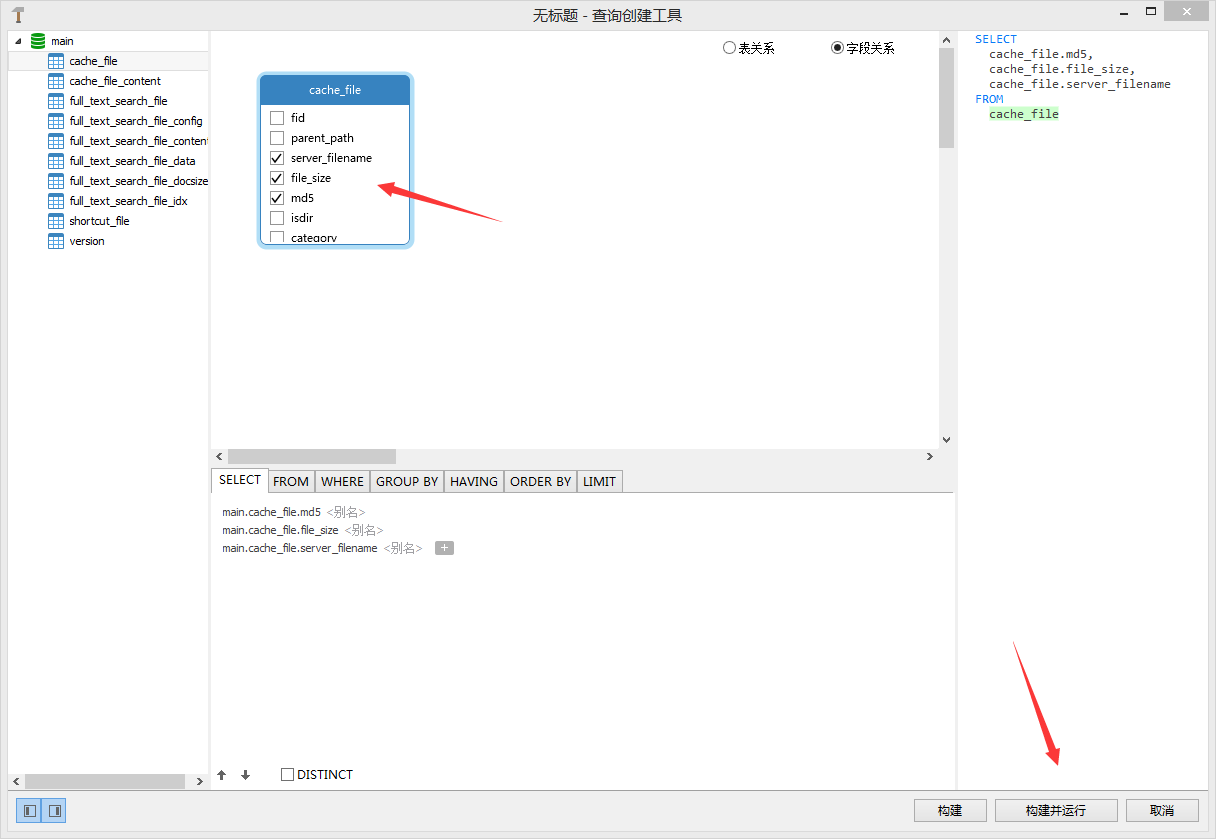
⑤.双击cache_file,按序依次勾选 md5、file_size、server_filename,点击 构建并运行;
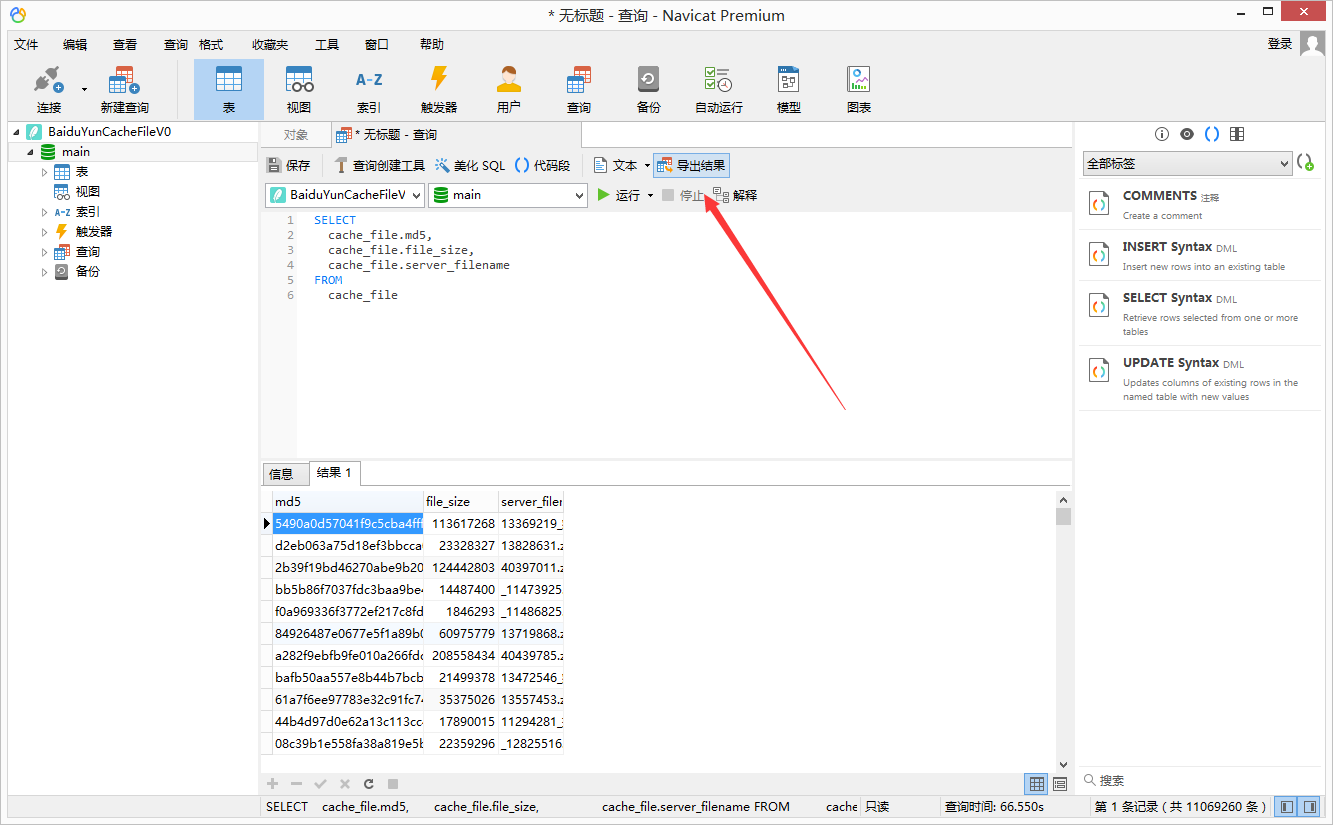
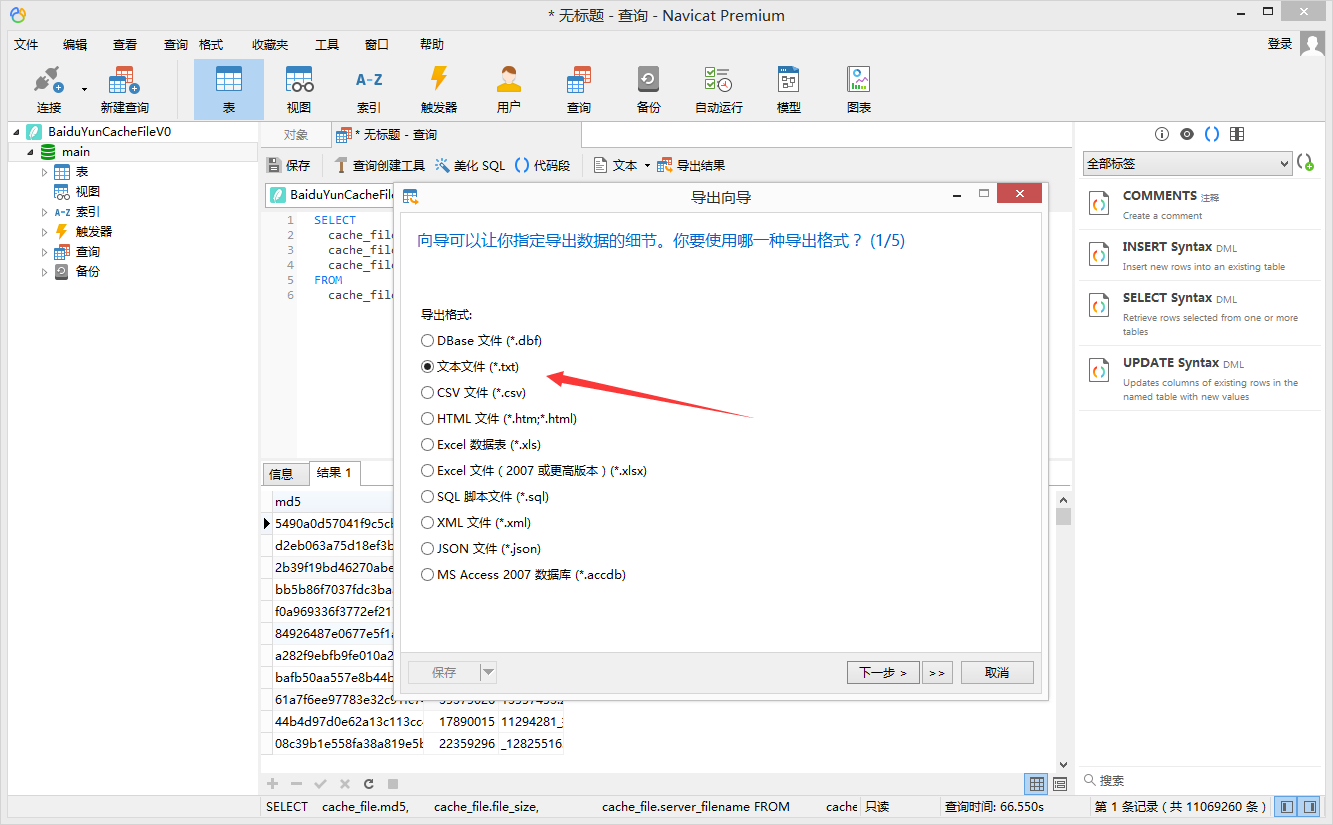
⑥.生成结果后,点击 导出结果,选择 文本文件txt,依次按下图示意勾选编辑;
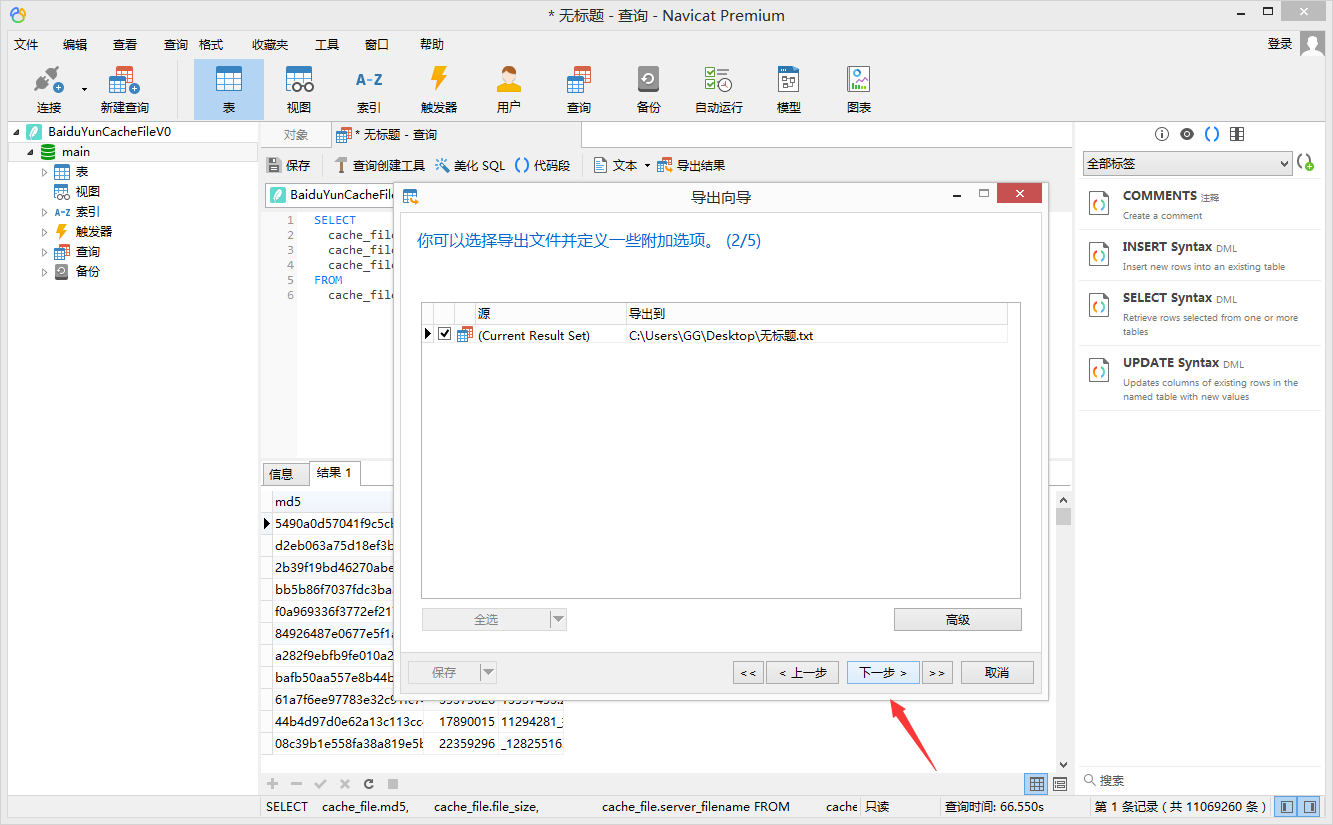
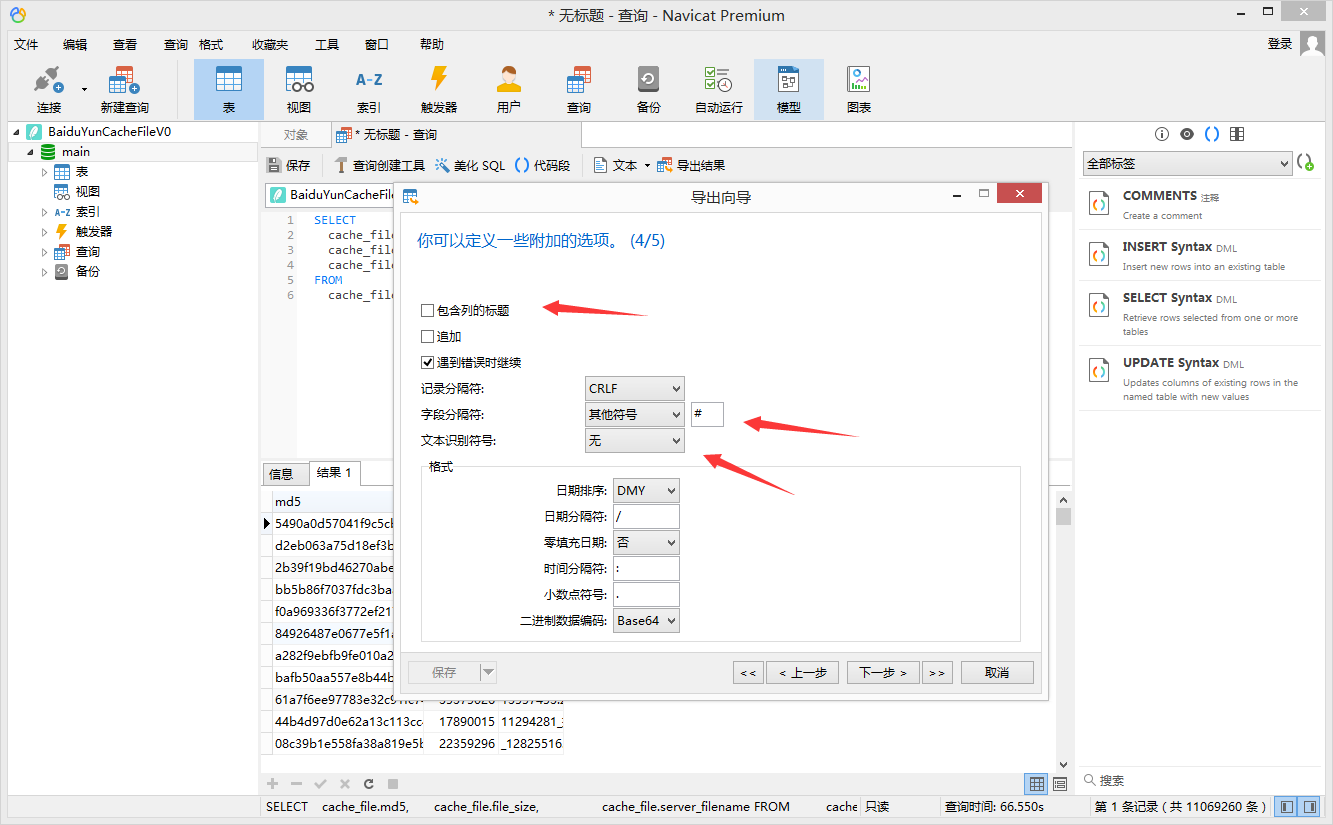
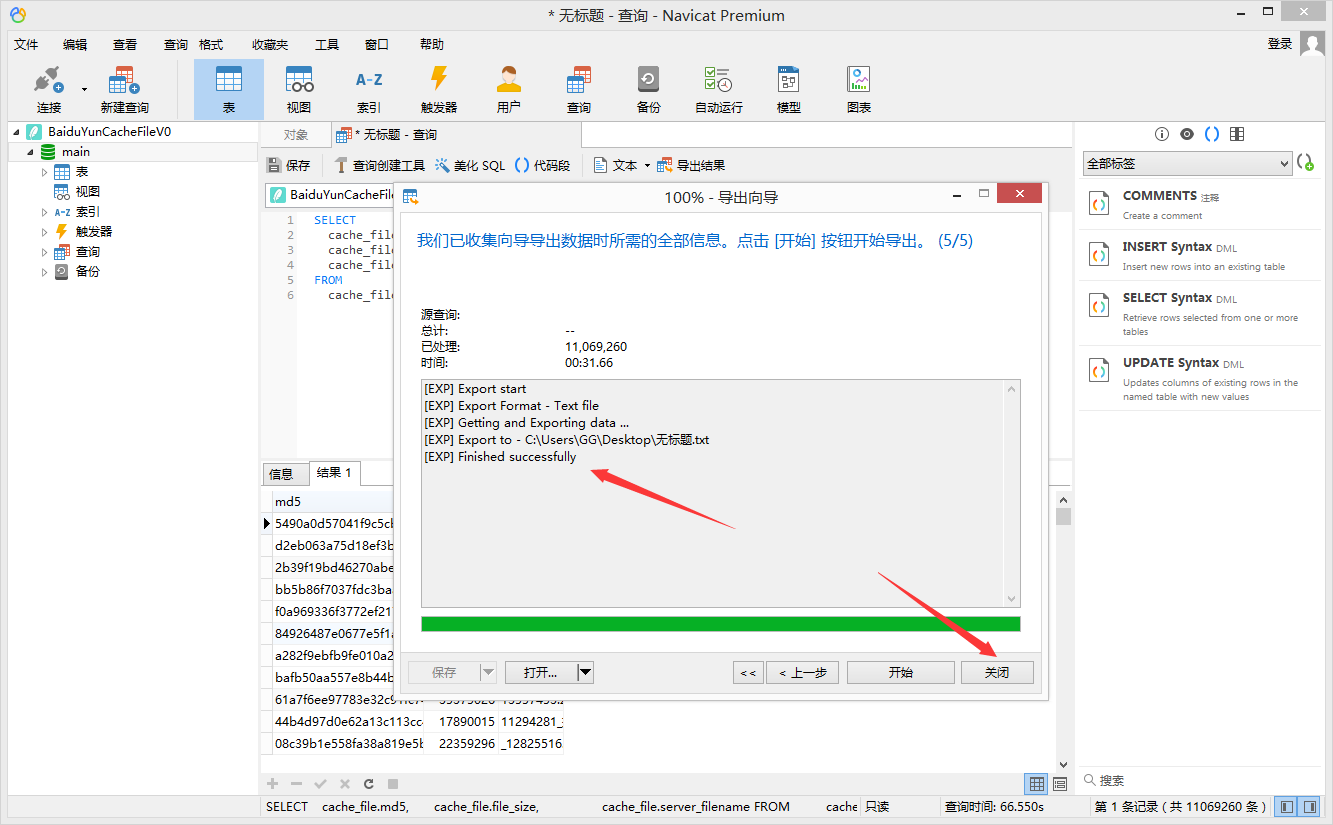
⑦.最终直接获得简版秒传码文档,如下图所示:
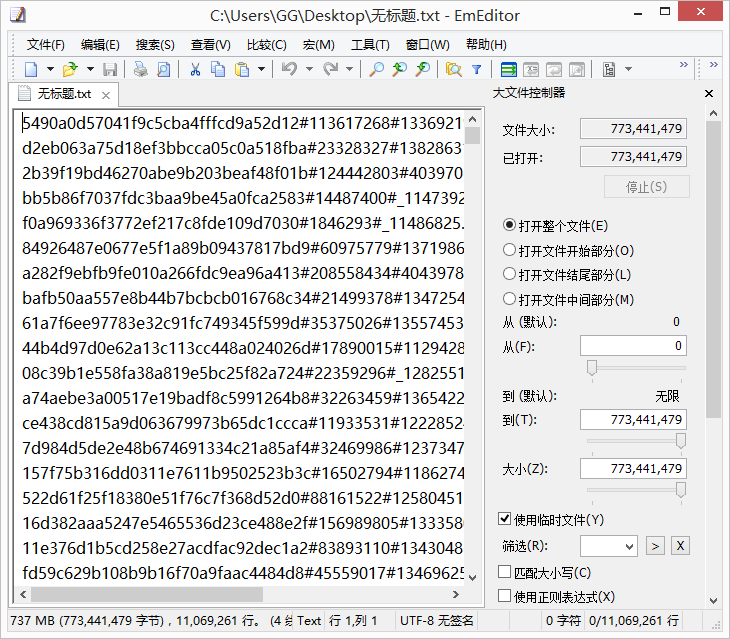
小结:
①.通过该简版秒传方案,目前已生成1440万册电子书,包含读秀2.0-5.0以及其他电子书库;
②.与方案一相同,可在本地搜索SS号或书名,搭配全国图书馆联盟、合成解密工具包使用;
总结:
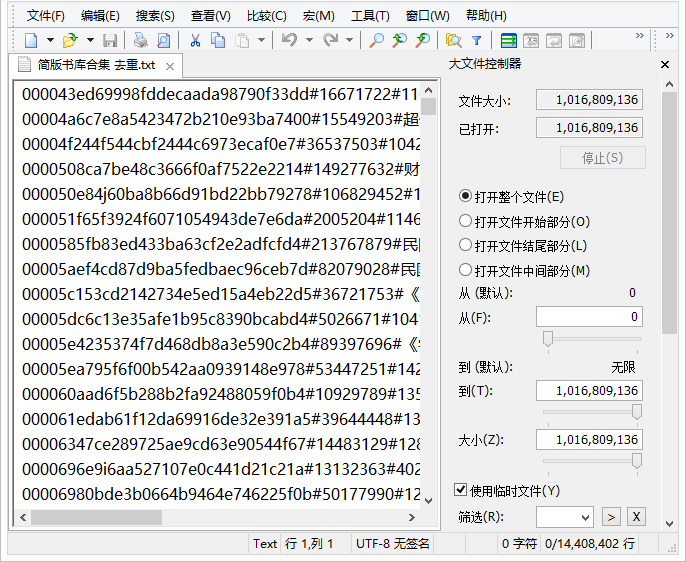
1、方案一标准秒传码,使用秒传脚本提取数据,目前已经更新到657万册;
2、方案四简版秒传码,基于多个大容量网盘缓存数据库生成数据,目前已经更新到1440万册;
3、生成速度比较:方案一较慢,脚本更新极速版后,速度有翻倍提升;方案二需要在网盘中查找定位,最慢;方案三需要一定编程基础,稍慢;方案四所有文件一次搞定,最快;
4、四种方案,基于前人公开文章以及热心网友经验总结而成,在此一并致谢,当然还有其他模式,比如命令行;欢迎联系交流,互通有无,共同进步。
五、交易
标准秒传码书库,657万册,仍然与之前相同,跳楼价300元;
简版秒传码书库,1440万册,特价150元,老用户如有意,只需30元;
联系方式(Base64 编码):UVHvvJoyNzgxMDA4MzE=
小众资源,没有多少人稀罕,纯属自娱自乐,非诚勿扰。 |
 嘟嘟社区
嘟嘟社区